DeepSeek
G pt 4 all Ai
满足你对卓越的渴望,共创无限可能! DeepSeek智能无限,点燃创意火花!它不仅是工具,更是灵感源泉,解锁潜能,让未来触手可及。每一次交互,都激发无限想象,释放内心激情。想要突破常规,拥抱更广阔的世界?
















































满足你对卓越的渴望,共创无限可能! DeepSeek智能无限,点燃创意火花!它不仅是工具,更是灵感源泉,解锁潜能,让未来触手可及。每一次交互,都激发无限想象,释放内心激情。想要突破常规,拥抱更广阔的世界?

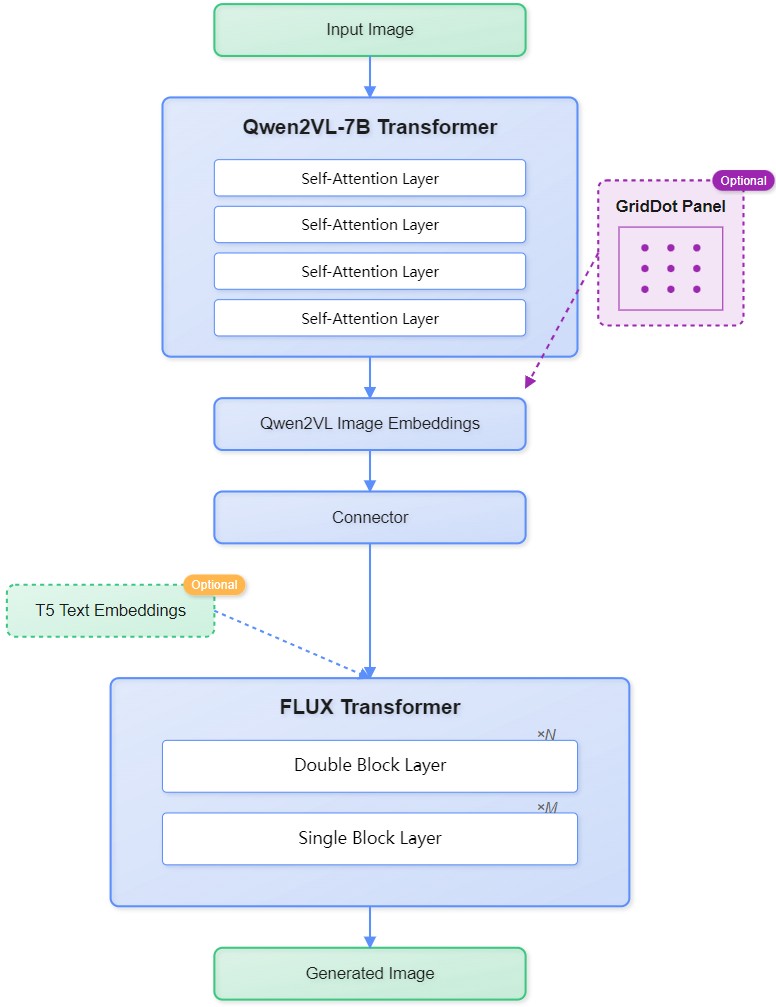






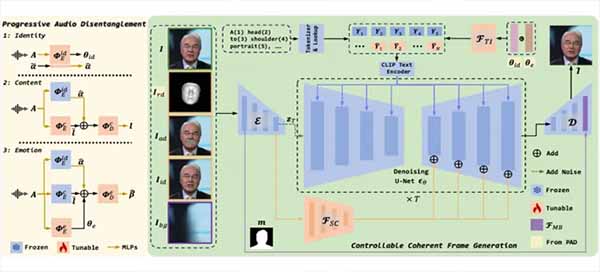
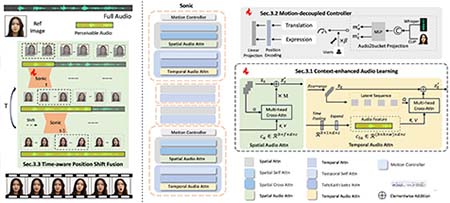
JoyVASA由京东健康与浙江大学联合研发,基于扩散模型实现音频驱动的面部动画生成,核心创新包括: